

◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。
要能采集网址的火车头,必须是7版以上的,以下的版本无法办到。
首先创建一个标签为本文网址,勾选后面的“从网址中采集”。
选择下面的“正则提取”,点击通配符“(??)”,这样在窗口中就显示为(?[\s\S]*?)
我们再在它前加一个与字符串开始的地方匹配的符号^,又在它后面加一个与字符串结束的地方匹配的符号$,这样就变成了^(?[\s\S]*?)$。如图:
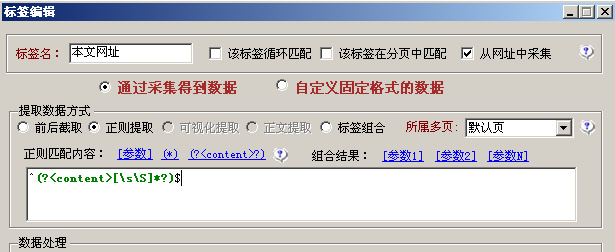
Content 代表内容
?
表示匹配0次或者1次
\s
匹配所有空白字符
\S
匹配所有非空白字符
*
修饰匹配次数为
0 次或任意次
更多正则表达知识,你也可以访问http://www.regexlab.com/zh/regref.htm
你可能想看:
喜欢这篇文章的读者还看了以下文章!